目标检测
这是目标检测学习所做的笔记,使用pytorch实现。东西很乱,而且截至目前还没有整理完,请见谅。
概要
- 目标检测相关技术演进
SSD算法YOLO算法
COCO: 目标检测数据集
- COCO(Common Objects in Context)是目标检测中比较常见的数据集,类似于Imagenet在图片分类中的地位
- COCO数据集中有80 个类别 ,330k 张图片 ,1.5M 物体 (每张图片中有多个物体)
Bounding Box (边缘框)
边缘框可以用4个数字定义,下面为两种常用的表示方法:
- (左上x,左上y,右下x,右下y)
- (中心x,中心y,宽,高)
使用第一种方法定义一个bounding box:
向下的方向为y轴的正方向。
1 | # bbox是边界框的英文缩写 |
两种形式可以通过如下方式进行转换,输入参数boxes可以是长度为4的张量,也可以是形状为(,4)的二维张量,其中是边界框的数量:
1 | def box_corner_to_center(boxes): |
我们可以通过转换两次来验证边界框转换函数的正确性。
1 | boxes = torch.tensor((dog_bbox, cat_bbox)) |
1 | tensor([[True, True, True, True], |
下面,将边界框在一张图中画出。在这之前,先导入需要加上边框的图片:
1 | %matplotlib inline |

定义一个辅助函数bbox_to_rect将边界框表示成matplotlib的边界框格式。
1 | def bbox_to_rect(bbox, color): |
在图像上添加边界框之后,我们可以看到两个物体的主要轮廓基本上在两个框内。
1 | fig = d2l.plt.imshow(img) |

IoU (Intersection Over Union, 交并比)
交并比是指两个集合的交集除以两个集合的并集:
$$J(A,B) = \frac{|A∩B|}{|A∪B|}$$

- 用于衡量锚框和真实边缘框之间的相似度,是两个框之间的交集与两个框的并集的比值
- 取值范围[0,1]:0表示没有重叠,1表示完全重合(越接近1,两个框的相似度越高)
- 它是Jacquard指数的特殊情况(给定两个集合,Jacquard指数表示两个集合的交集和两个集合的并集之间的比值)
在接下来部分中,我们将使用交并比来衡量锚框和真实边界框之间、以及不同锚框之间的相似度。 给定两个锚框或边界框的列表,以下box_iou函数将在这两个列表中计算它们成对的交并比。
1 | def box_iou(boxes1, boxes2): |
锚框
h: 输入图片的高度
w: 输入图片的宽度
s: scale, 锚框的大小(相对于整张图片大小的比例)
r: aspect ratio, 锚框的高宽比
锚框的宽度和高度分别是$ws\sqrt{r}$和$hs/\sqrt{r}$
- 锚框的类别(class,与锚框相关的对象的类别)
- 锚框的偏移量(offset,真实边缘框相对于锚框的偏移量)标签
从图片分类到目标检测
labels (标签)
图片分类中,神经网络输出每个类的概率,经softmax确定预测的one-hot编码,输出为:$ \begin{bmatrix} c_1 & c_2 & … & c_n \end{bmatrix}^T $,其中,$c$为每一类的标号,如对猫狗分类而言$\begin{bmatrix} 1 & 0\end{bmatrix}^T$可以为猫,则$\begin{bmatrix} 0 & 1\end{bmatrix}^T$为狗。对于锚框而言,输出为:
$$
\begin{bmatrix}p_c & b_x & b_y & b_h & b_w & c_1 & c_2 & c_3\end{bmatrix}^T
$$
其中,$p_c$表示其中是否检测到目标,若其为0则后续标签均可忽略,$b$表示目标的位置,$b\in[0, 1]$。
loss function (损失函数)
对于损失函数Loss function,若使用平方误差形式,有两种情况:
- $P_c=1$,即$y_1=1$:
$$
(\hat{y},y)=(\hat{y}_1−y_1)^2+(\hat{y}_2−y_2)^2+⋯+(\hat{y}_8−y_8)^2
$$ - $P_c=0$,即$y_1=0$:
$$
(\hat{y},y)=(\hat{y}_1−y_1)^2
$$
当然,除了使用平方误差之外,还可以逻辑回归损失函数,类标签$c_1$ $c_2$ $c_3$也可以通过softmax输出。比较而言,平方误差已经能够取得比较好的效果。
应用
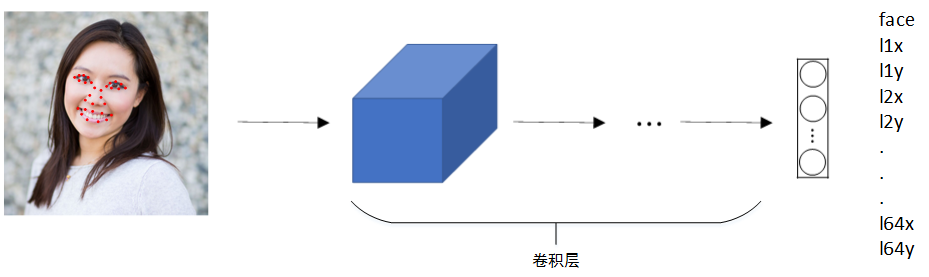
可以使用上述方式对人脸部分特征点坐标进行定位检测(Landmark Detection),并标记出来:
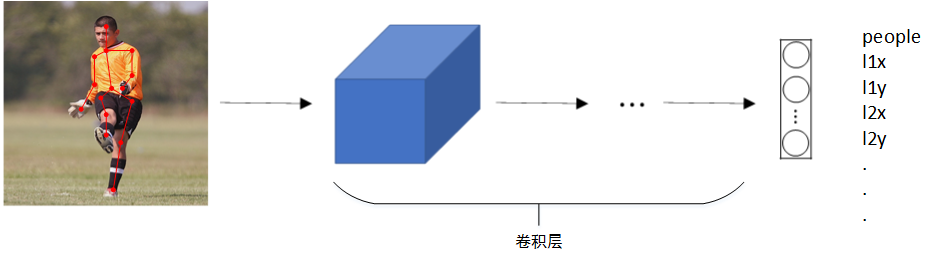
也可以检测人体姿势动作:
Sliding Windows (滑动窗算法)
算法流程
使用滑动窗算法实现Object Detection有以下几步:
- 训练图片分类网络
- 在测试图片上选择大小适宜的窗口、合适的步进长度,进行从左到右、从上到下的滑动。每个窗口区域都送入之前构建好的CNN模型进行识别判断,若判断有目标,则此窗口即为目标区域;若判断没有目标,则此窗口为非目标区域。

算法优缺点
- 优点:原理简单,不需要人为选定目标区域(检测出目标的滑动窗即为目标区域)。
- 缺点:
- 需要人为设定滑动窗的大小和步进长度。滑动窗过小或过大,步进长度过大会降低目标检测正确率。
- 每次滑动窗区域都要进行网络计算,算法运行时间长。
滑动窗算法虽然简单,但是性能不佳、不够灵活。
Convolutional Implementation of Sliding Windows
滑动窗算法可以使用卷积方式实现以提高运行速度、节约重复运算成本。
首先将全连接层转变成为卷积层,如下图所示:
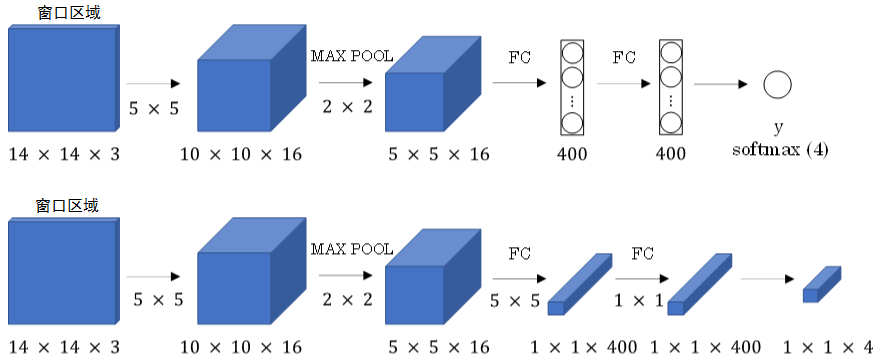
全连接层转变成卷积层的操作很简单,只需要使用与上层尺寸一致的 filter 进行卷积运算即可。最终得到的输出层维度是 1×1×4,代表 4 类输出值。
单个窗口区域卷积网络结构建立完毕之后,对于待检测图片,即可使用该网络参数和结构进行运算。例如 16×16×3 的图片,步进长度为 2,CNN网络得到的输出层为 2×2×4。其中,2×2 表示共有 4 个窗口结果;28×28×3 的图片,输出层为 8×8×4,共 64 个窗口结果。
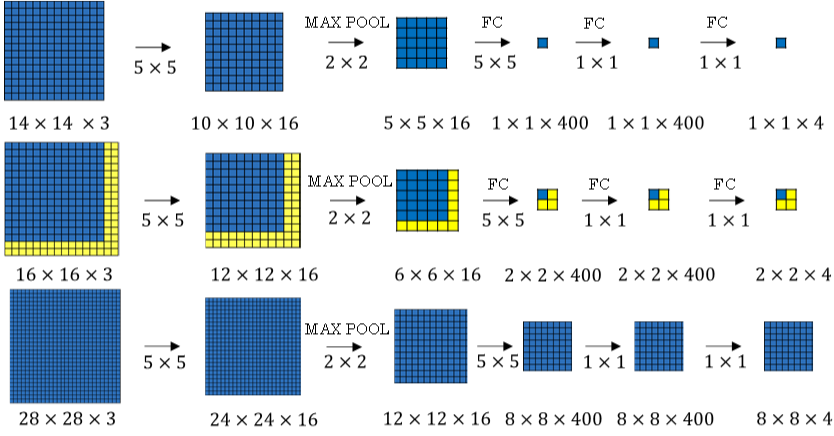
之前的滑动窗算法需要反复进行正向计算,例如 16×16×3 的图片需进行 4 次,28×28×3 的图片需进行 64 次。而利用卷积操作代替滑动窗算法,则不管原始图片有多大,只需要进行一次正向计算,大大节约了运算成本。窗口步进长度与选择的 Max Pool 大小有关。如果需要步进长度为 4,只需设置Max Pool 为 4×4 即可。
Bounding Box Predictions
滑动窗口算法有时会出现滑动窗不能完全涵盖目标的问题,如下图蓝色窗口所示。YOLO(You Only Look Once)算法可以解决这类问题,生成更加准确的目标区域(如上图红色窗口)。

YOLO算法首先将原始图片分割成n×n网格,每个网格代表一块区域。为简化说明,下图中将图片分成3×3网格。
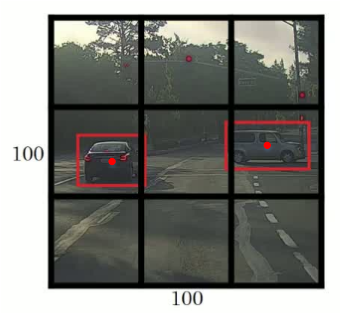
然后,利用上一节卷积形式实现滑动窗口算法的思想,对该原始图片构建CNN网络,得到的的输出层维度为 3×3×8。其中,3×3 对应 9 个网格,每个网格的输出包含 8 个元素:
$$
output=\begin{bmatrix}p_c & b_x & b_y & b_h & b_w & c_1 & c_2 & c_3\end{bmatrix}^T
$$
如果目标中心坐标($b_x$, $b_y$)不在当前网格内,则当前网格$p_c=0$;相反,则当前网格$p_c=1$(即只看中心坐标是否在当前网格内)。判断有目标的网格中,$b_x$, $b_y$, $b_h$, $b_w$限定了目标区域。值得注意的是,当前网格左上角坐标设定为(0, 0),右下角坐标设定为(1, 1),($b_x$, $b_y$)范围限定在[0,1]之间,但是$b_h$, $b_w$可以大于1。因为目标可能超出该网格,横跨多个区域,如上图所示。目标占几个网格没有关系,目标中心坐标必然在一个网格之内。划分的网格可以更密一些。网格越小,则多个目标的中心坐标被划分到一个网格内的概率就越小。
Non-max Suppression (NMS, 非极大值抑制)
对于多个网格都检测出到同一目标的情况,使用NMS算法得出最为准确的网格
- 计算每个网格的$p_c$值,$p_c$值反映了该网格包含目标中心坐标的可信度。
- 选取$p_c$值最大值对应的网格和区域
- 计算该区域与所有其它区域的IoU
- 剔除掉IoU大于阈值(例如0.5)的所有网格及区域。这样就能保证同一目标只有一个网格与之对应,且该网格Pc最大。
- 返回
步骤2。
最后,就能使得每个目标都仅由一个网格和区域对应。
以下nms函数按降序对置信度进行排序并返回其索引。
1 | def nms(boxes, scores, iou_threshold): |
定义函数multibox_detection使用nms将非极大值抑制应用于预测边界框:
1 | def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5, |
Anchor Box (锚框)
到目前为止,我们介绍的都是一个网格至多只能检测一个目标。那对于多个目标重叠的情况,例如一个人站在一辆车前面,该如何使用YOLO算法进行检测呢?方法是使用不同形状的Anchor Boxes。
如下图所示,同一网格出现了两个目标:人和车。为了同时检测两个目标,我们可以设置两个Anchor Boxes,Anchor box 1 检测人,Anchor box 2 检测车。也就是说,每个网格多加了一层输出。原来的输出维度是 3×3×8,现在是 3×3×2×8(也可以写成 3×3×16 的形式)。这里的2表示有两个Anchor Boxes,用来在一个网格中同时检测多个目标。每个Anchor box都有一个Pc值,若两个Pc值均大于某阈值,则检测到了两个目标。
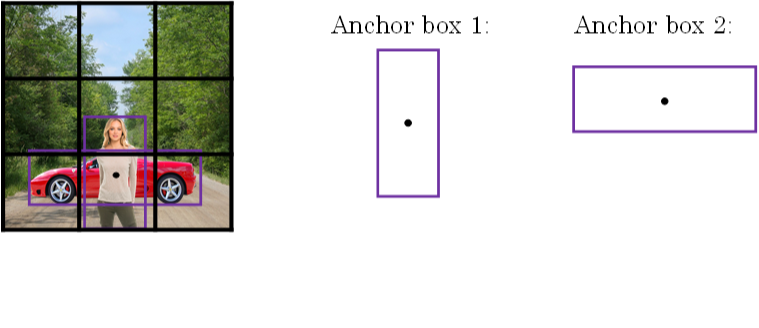
对于有两个锚框的情况,输出的格式如下:
$$
output=\begin{bmatrix}p_c & b_x & b_y & b_h & b_w & c_1 & c_2 & c_3 & p_c & b_x & b_y & b_h & b_w & c_1 & c_2 & c_3\end{bmatrix}^T
$$
在使用YOLO算法时,只需对每个 Anchor box 使用非最大值抑制即可。Anchor Boxes形状的选择可以通过人为选取,也可以使用其他机器学习算法,例如k聚类算法对待检测的所有目标进行形状分类,选择主要形状作为Anchor Boxes。
YOLO
- For each grid call, get 2 predicted bounding boxes.
- Get rid of low probability predictions.
- For each class (pedestrian, car, motorcycle) use non-max suppression to generate final predictions.